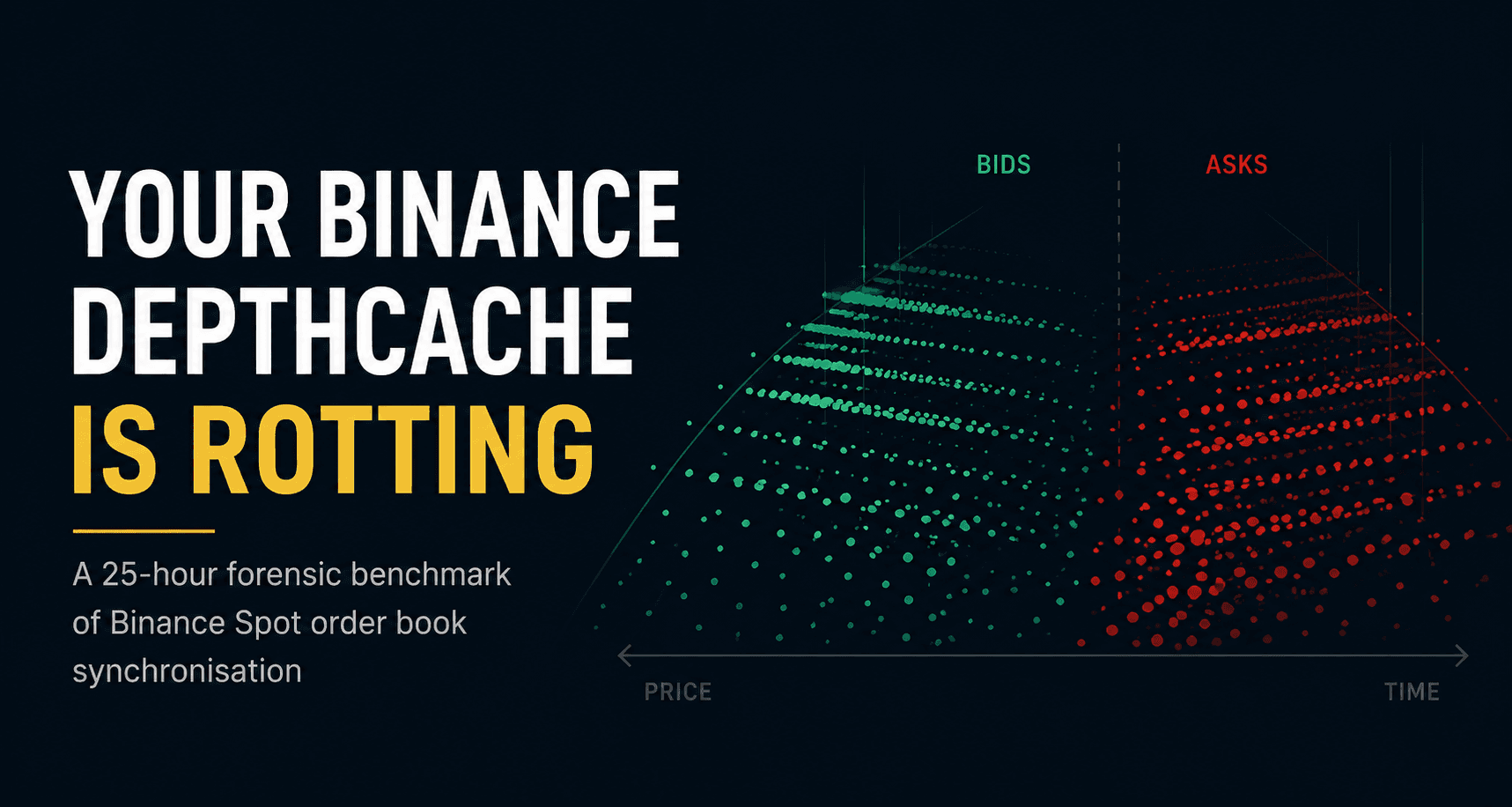
Your Binance DepthCache is rotting — here's the proof in 25 hours
A 25-hour forensic benchmark showing why Binance Spot DepthCaches need an explicit retention policy — not just correct synchronization.
A local Binance Spot order book can look healthy at the top and still be structurally wrong underneath.
Not “a little bit noisy”. Not “slightly delayed”. Wrong in the way that only shows up when you stop looking at best bid / best ask and audit the whole local book.
After a single quiet day on BTCUSDT, my naive no-retention DepthCache ended up with only 24.09% matching bid levels and 39.82% matching ask levels. Most of the local book had turned into ghosts: price levels still present locally, but no longer present in a fresh REST snapshot.
I have known about this class of problem for years. So have other people who have shipped trading systems against Binance. Most of us learned it the hard way, patched our own systems, and moved on.
I already wrote up the mechanism in Your Binance Order Book Is Wrong — Here's Why. That article explains the bug class. This one is the forensic benchmark: the same problem measured over 25 hours with a naive implementation and a pruned implementation running side by side.
This time I wanted numbers.
So I ran two DepthCaches side by side for 25 hours, fed by the same WebSocket stream, audited hourly against fresh REST snapshots, and plotted the decay in 3D.
Here is the proof.
What a DepthCache is, and what the Binance docs say
A DepthCache (DC) is a local mirror of the order book. You keep bids and asks per price level in memory and update them from the exchange stream, so your strategy does not need to hit REST every time it wants to know where the book currently is.
Binance documents how to manage a local Spot order book. The current guide is better than many older code examples floating around: it uses a REST snapshot with limit=5000, explains how to align buffered WebSocket events with lastUpdateId, and explicitly documents update-ID continuity checks.
Short version of the official flow:
Open a WebSocket to
<symbol>@depth.Buffer events.
Fetch
GET /api/v3/depth?symbol=...&limit=5000.Align buffered events with the snapshot's
lastUpdateId.Apply updates in order.
If an event proves you missed updates, discard the local book and restart from a fresh snapshot.
For every streamed price level, set the new quantity; if quantity is zero, remove the level.

The important part is not what Binance gets right here. The guide does document update continuity. It also warns that because REST snapshots are limited to 5000 levels per side, you will not know quantities for levels outside the initial snapshot unless those levels change, and that those levels may not reflect the full view of the order book.
That warning is the key.
The guide tells you how to synchronize and how to apply events. It does not define a retention policy for a bounded local cache. It does not say what your local book's maximum depth should be after hours of streamed updates. It does not say when to evict levels that entered through the stream but are no longer inside the view you can validate.
That missing retention rule is where the rot starts.
What the stream actually does
The depth stream does not care about the conceptual depth corridor your local application wants to maintain.
In practice, it can send updates for levels far away from the current mid price: ladders placed and pulled 2% away from mid, deep ask-side repricing, limit orders parked far away in case of a flash move, and other book activity that your local cache may not have a stable baseline for.
A naive DC applies those updates anyway.
It sees a price level. It inserts it. The normal update procedure removes that level only if a later qty=0 arrives for the same price. Sometimes that cleanup event never arrives in a way your local cache can rely on. The level may have been cancelled, replaced, moved, or simply fallen out of the region that your local implementation still validates.
So it stays.
And then the next one stays.
And the next one.
After a few hours, your local order book is no longer a bounded view of the exchange book. It is a growing collection of historical levels.
I once discussed this exact class of problem with a Binance engineer in Telegram. The takeaway was clear: production systems cannot stop at basic synchronization; they need their own pruning, gap handling, and resync logic.

This is not a new class of problem. A public Binance depth-cache note from 2017 already described the same operational issue: if the order book shifts far enough from the snapshot, a local book can miss levels, and the implementation has to track that shift and resync.
Historical Binance Depth Cache Notes
This eventually became a tracked issue while I was debugging drift in my own UNICORN Binance Local Depth Cache implementation:
https://github.com/oliver-zehentleitner/unicorn-binance-local-depth-cache/issues/45
But a known issue is not the same as a measured failure mode.
So I measured it.
The setup
I ran two DepthCaches. Same symbol, same stream, same audit schedule.
Only one thing changed.
naive— insert streamed levels, update quantities, remove only onqty=0, no active pruning / retention policy.fixed— same initialization and update logic, but with active pruning back to the top-1000 levels per side after applied updates.
This benchmark uses a top-1000 target corridor on purpose. That makes the experiment smaller, faster to inspect, and more brutal in the charts. It is not claiming that Binance's current documentation says to initialize with limit=1000; the current guide says limit=5000.
The tested failure mode is more specific and more important:
What happens when a local order book inserts streamed price levels but does not enforce an active retention boundary?
A larger initial snapshot gives you a wider starting view. It does not by itself define what to do with streamed levels after the local book has been running for hours. Without a retention policy, the same class of stale-level accumulation still exists — just with a wider corridor and a different time profile.
The fixed variant is intentionally minimal. It does not include full UBLDC behavior. UBLDC also does update-ID gap detection and full resync on protocol violations. Binance documents that continuity check, and production code should implement it. I left it out of fixed deliberately, because this experiment isolates one variable only: pruning.
Both DCs were fed by the same WebSocket subscription via UBWA: one stream, two consumers.
Both were audited against the same REST snapshots at the same timestamps.
So any difference between naive and fixed comes from the retention strategy, not from feed drift.
The audit ran once per hour, with one extra audit immediately after initial sync and another after five minutes. Each audit fetched a fresh REST snapshot with limit=5000 and classified every local price level as one of:
match— level exists in REST and local cache, quantity is equaldrift— level exists in both, but quantity differsorphaned— level exists locally, but not in REST ← the important onemissed— level exists in REST, but not locally
The limit=5000 audit snapshot is deliberate. It checks whether a locally orphaned level is still alive deeper in REST's view, or whether it is stale relative to Binance's largest public REST snapshot.
One important methodology note: missed will show roughly 4000 levels per side for both variants. That is expected. REST returns 5000 levels, but both DCs only claim to maintain a top-1000 corridor. Those 4000 are not the failure.
The health metric that matters here is:
How much of the local cache still matches REST?
Results
The run lasted 25.10 hours on BTCUSDT, from 2026-04-28 08:51 to 2026-04-29 10:18 Europe/Vienna time.
BTC was calm during the window: total mid-price range was only 1.88%, with no flash event.
That matters. A quiet market is the easy case. More movement means more old levels falling out of the active region and more stale levels accumulating. So these numbers are not worst-case. They are probably closer to a lower bound for this no-retention pattern.
The headline chart

Open interactive chart: comparison.html
Final numbers
| n_bids | n_asks | bid_match | ask_match | total_orphaned | pruned (cumulative) | |
|---|---|---|---|---|---|---|
naive (audit #27) |
20 758 | 9 116 | 24.09% | 39.82% | 21 244 | — |
fixed (audit #27) |
1 011 | 1 078 | 87.83% | 91.74% | 305 | 295 121 |
The naive DC starts almost perfect. At t=0 it has 99.6% bid match.
Then it rots.
For the first six hours, the decay is roughly linear. After that, it plateaus with only about a quarter to a third of bid-side local levels still matching REST.
The fixed DC stays in the 75-97% match range over the full run. The lower bound around audit #15, #20, and #24 corresponds exactly to audits taken right after WebSocket reconnects; the run log confirms reconnect events at those audit timestamps.
There were 10 reconnects total, all auto-recovered by UBWA, but each reconnect can leave a small update-ID gap. Pruning cannot repair that. Gap detection and resync can.
That is exactly why production-grade DC logic needs both:
pruning, to prevent stale levels from accumulating
gap detection and resync, to recover from broken update continuity
The 3D scatter
The 3D plots make the failure obvious.

Open interactive 3D chart: report_naive.html
Warning: large Plotly file, about 78 MB.

Open interactive 3D chart: report_fixed.html
Warning: large Plotly file, about 41 MB.
In the naive plot, the red orphaned tail is the story.
It is not random noise. It forms a coherent ribbon of dead levels trailing the mid price. As the market moves, levels that were once near the active book fall out of the bounded view. The naive cache never evicts them.
So they become ghosts.
The fixed plot is what a bounded local book should look like. The remaining orange and red points near the top of book are explainable by audit-time race conditions and reconnect gaps. Those are separate, known problems. They are not evidence against pruning.
The forensic plots
For anyone tempted to call this measurement error, the forensic plots tell the same story from different angles.
Distance of orphaned levels from mid: orphaned levels cluster around ±0.5-2% from the mid price. They are shaped by market movement. The tails get fatter audit by audit because old levels accumulate.

Open interactive chart: distance_naive.html
Age of orphaned levels: for every orphaned level in the final audit, I checked all 27 archived REST snapshots and asked when REST last contained that price.
The result is bimodal:
a smaller group of recently rotted levels, last seen 1-5 hours ago
a huge spike at “never seen”
That second group is important. These levels arrived through the diff stream, but were never present in any archived REST limit=5000 snapshot. They entered the local cache from outside the audited REST corridor and then stayed there as dead weight.

Open interactive chart: age_naive.html
Volatility correlation: per-hour growth in orphaned levels correlates with per-hour absolute mid-price movement. More movement, more rot.
The biggest single-window mid move in this run was only 0.07%. Even that modest move produced a visible orphaned-level jump. On a flash-down or high-volatility day, this would look much worse.

Open interactive chart: volatility_naive.html
Why it happens, in one paragraph
The REST snapshot gives you a bounded initial view. The diff stream can then deliver updates for price levels outside the view your application intends to maintain. The documented update procedure tells you how to apply those updates and how to detect broken update continuity, but it does not define a long-running retention policy for a bounded local cache. So a naive implementation inserts levels it cannot reliably validate later, and keeps them until it happens to receive a cleanup update. There is no safe operational guarantee that this will happen for every deep level before the local book becomes polluted. Over time, the cache accumulates orphaned price levels. After 25 quiet hours, the naive DC contains tens of thousands of stale levels and no longer resembles Binance's largest public REST snapshot outside the very top of book.
What to do
There are three sane options.
1. Use something that explicitly handles this.
UBLDC (UNICORN Binance Local Depth Cache) does bounded book maintenance, stale-level pruning, update-ID gap detection, and full resync on protocol violations. Yes, I work on it, so I am biased. But the real point is broader:
Do not trust a DepthCache implementation just because it can follow the Binance synchronization steps.
Trust it only if it can explain these things:
What is the maximum local depth per side after 24 hours?
Which levels are allowed to stay in memory?
When are stale levels evicted?
How is update-ID continuity verified?
What happens after a WebSocket reconnect?
When is the local book discarded and rebuilt?
If your library or internal implementation cannot answer those questions, it is probably not production-safe.
2. Roll your own with active pruning.
If you have a reason to maintain your own DC code, the minimum additional logic is active pruning back to the depth corridor you can actually validate.
# After applied updates:
if len(bids) > top_n:
keep = sorted(bids.keys(), reverse=True)[:top_n]
bids = {p: bids[p] for p in keep}
if len(asks) > top_n:
keep = sorted(asks.keys())[:top_n]
asks = {p: asks[p] for p in keep}
In production, you would usually prune with a small tolerance window instead of sorting on every single update. The invariant is the same: the local book must not be allowed to grow beyond the depth corridor you can actually validate.
That alone took this experiment from a rotting book — roughly 24% bid match and 40% ask match — to a much healthier 88% bid match and 92% ask match.
It is not a micro-optimization. It is correctness logic.
3. Detect gaps and resync.
Pruning fixes stale-level accumulation. It does not fix broken update continuity.
Each diff event has U and u fields. Binance documents that if an event's first update ID is greater than your local update ID + 1, you missed events and must discard the local order book and restart from the beginning.
That can happen during WebSocket reconnects, server-side hiccups, local buffering problems, network loss, or payload backpressure.
When it happens, do not “continue carefully”. Discard the local book and reinitialize from a fresh REST snapshot.
The 10 reconnects during this run are visible in the fixed variant as small match% dips. They are not solved by pruning. They are solved by gap detection plus resync.
A production DepthCache needs both.
Reproducibility
The supplementary material index is here:
https://oliver-zehentleitner.github.io/binance-depthcache-forensics
The public GitHub repository is here:
It tracks the GitHub Pages index, interactive chart links, raw audit data, and benchmark context.
The whole experiment is about 600 lines of Python (dc.py, audit.py, plotter.py, run.py, analysis.py) plus the unicorn-binance-websocket-api dependency and Plotly.
The raw data is available here:
https://oliver-zehentleitner.github.io/binance-depthcache-forensics/raw_data.tar.gz
It contains the audit JSON files, archived REST snapshots, and run logs. If you want to verify a number from this article, it is in there.
Supporting charts are also available:
Related reading
If you want the shorter conceptual version before the benchmark, start here:
That article explains the failure mode. This article proves how fast and how far it accumulates in a real run when no active retention policy is enforced.
Final note
If you currently run a trading strategy against a DepthCache you wrote yourself, dump it and compare it against a fresh REST snapshot.
Not the best bid.
Not the first ten levels.
The whole local book.
You may not like what you find.
I hope you found this informative and useful.
Follow me on Binance Square, GitHub, Mastodon, X, and LinkedIn, or join Telegram for updates on my latest publications. Constructive feedback is always appreciated.
Thank you for reading, and happy coding! ¯\_(ツ)_/¯




