UBDCC Deep-Dive: Building a Trust Layer for Binance Order Books
How a stack of small Python pieces — UBWA, UBLDC, UBDCC, the Dashboard — turns a Binance order book from "I have data" into "I have a trusted data source", and where gRPC fits in next.
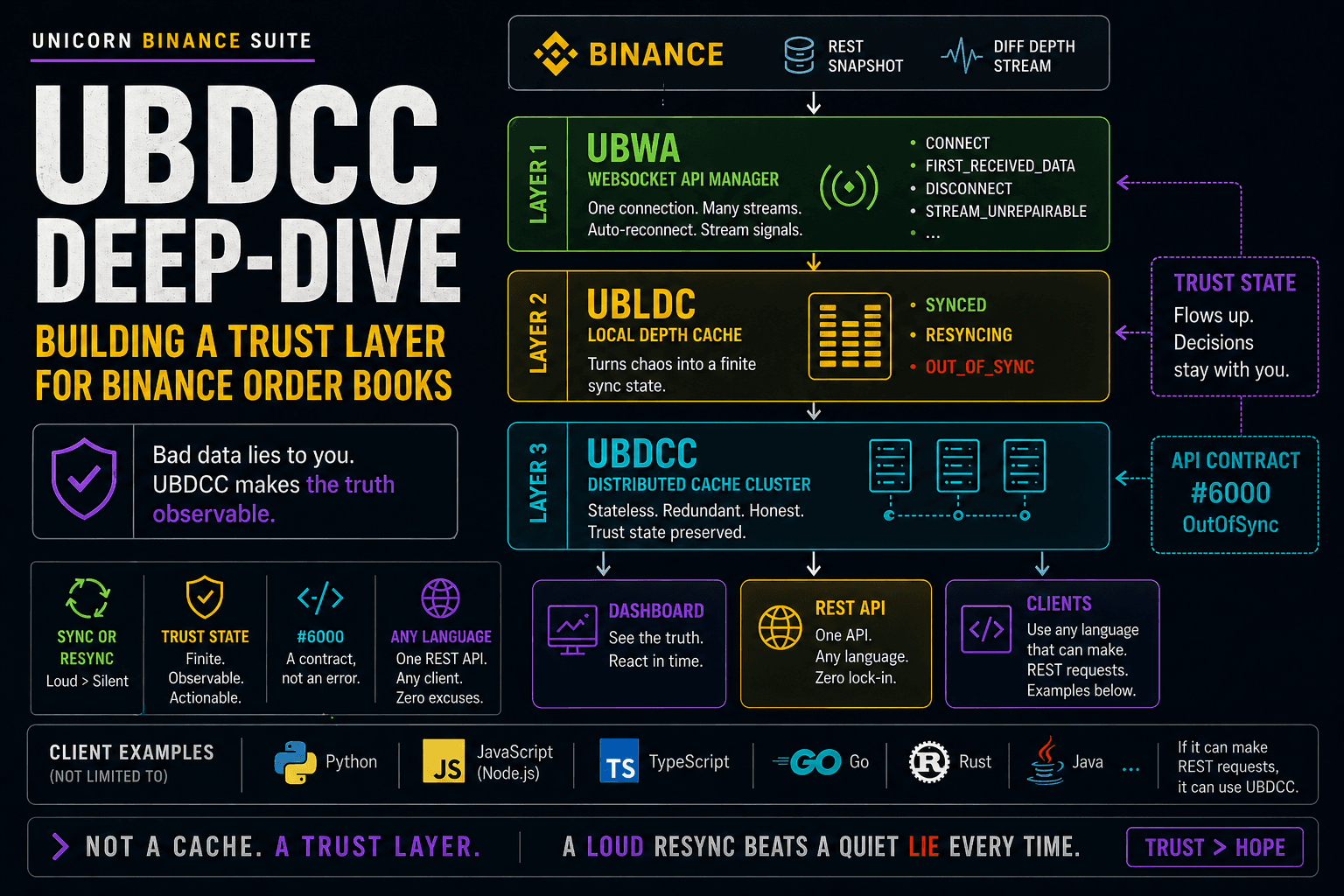
TL;DR — UBDCC is not "Redis for Binance order books". It is an order book trust layer: every layer of the stack — UBWA, UBLDC, the cluster, the dashboard — exists to turn a stream of binary diff messages into a finite, observable trust state your strategy can reason about. This post walks the stack end to end.
The previous post was the five-minute install: pip install ubdcc, kill a node, watch failover, copy a snippet from the API Builder, done.
This post is the why. What every layer is doing, why it exists, and how the pieces add up to something far more important than "we cached a JSON object".
Because in trading infrastructure, a wrong order book is worse than no order book. No data stops you. Bad data lies to you.
The framing comes out of a LinkedIn discussion on the quickstart. One reader put it sharper than I had so far:
"OutOfSync is not just an exception name. It is a finite trust state that the rest of the system can reason about."
That is the thread we are pulling here.
By the end of this post, you should understand:
why a Binance order book can be wrong while still looking perfectly valid
how UBLDC turns snapshots and diff streams into a finite sync state
how UBDCC preserves that trust state across HTTP
why
#6000is a feature, not just an errorwhere REST is enough, and where gRPC starts to make sense

Layer 0 — What Binance actually gives you
Before any code, let's be honest about the raw material. Binance does not hand you truth. It hands you puzzle pieces.
Binance does not expose "the order book". It exposes two things:
A REST snapshot at a specific
lastUpdateId. One HTTP call. For futures and options it is reasonably fresh; for European Options it is cached server-side for ~30 seconds, which becomes important later.A diff-depth WebSocket stream of incremental updates, each tagged with
U(first update id) andu(final update id), and on futures additionallypu(previous final update id).
To turn that into a usable order book you have to:
Fetch the snapshot.
Buffer diffs that arrive while the snapshot is in flight.
Find the sync point: the first diff where
U <= lastUpdateId+1 <= u(spot) orU <= lastUpdateId <= u(futures/options).Apply diffs sequentially, validating that each
Uequals the previousu + 1(spot) or eachpuequals the previousu(futures).Re-sync from scratch the moment a gap appears.
Quietly accept that price levels which fall outside the top 1000 get no delete event. Binance just stops mentioning them. If you follow the docs literally, those levels stay in your book forever as ghost orders.
Most "order book" libraries do step 1, half of step 4, and then quietly hope reality stays polite.
Reality does not.
That is where silent corruption starts: the book still looks like an order book, the numbers still parse, your strategy still runs — but the data is no longer trustworthy.
The whole UBS stack exists to handle the rest of that list — and to make the result observable.
Layer 1 — UBWA: the event bus
UBWA is the WebSocket layer underneath everything. From the trust-layer perspective its job is simple to say and annoying to implement: turn an unreliable TCP connection to Binance into a clean event source for whatever sits on top.
What UBWA gives you that you would otherwise write yourself:
One process, many streams. A single
BinanceWebSocketApiManagermultiplexes hundreds of subscriptions across multiple physical connections, respecting Binance's per-connection subscription cap.Auto-reconnect with state. When a socket drops, UBWA reconnects, re-subscribes, and emits a signal for every stream it touched so consumers can react.
Stream signals as a first-class API. Pass
process_stream_signals=...(or enablestream_signal_buffer) and every reconnect, disconnect, first-message-after-connect arrives as a structured event:def on_signal(signal_type, stream_id, data_record=None, error_msg=None): # signal_type ∈ CONNECT, DISCONNECT, FIRST_RECEIVED_DATA, # STREAM_UNREPAIRABLE, NEW_STREAM_STARTED, ... ...This matters for the trust layer because it means UBLDC does not have to guess whether a stream gap was a real Binance gap or a socket reconnect. It gets told.
Async-queue access to data.
ubwa.get_stream_data_from_asyncio_queue(stream_id)is what UBLDC's diff loop awaits on. UBWA decouples the network side completely from the consumer side — consumers can fall behind without losing events, up to a configurable buffer cap.
UBWA is the only place in the stack that has to care about TCP chaos. Everything above it works in terms of ordered messages plus explicit connection signals. That separation is what keeps the next layer sane.

Layer 2 — UBLDC: the sync state machine
UBLDC sits on top of UBWA and is where the order book actually exists. It is also where most of the interesting decisions live. If UBWA is the event bus, UBLDC is the part that asks the uncomfortable question: "Can I still trust this book?"
For each market UBLDC keeps a small state record:
{
"asks": {...},
"bids": {...},
"is_synchronized": False,
"last_update_id": None,
"last_refresh_time": None,
"refresh_request": True,
"refresh_interval": <int|None>,
"stream_status": None,
}
Three flags do most of the work: is_synchronized, refresh_request, last_update_id. The whole loop in _manage_depth_cache_async() is a state machine over those.
Bootstrapping a market
When a market is added, refresh_request is True and is_synchronized is False. Diff events start arriving immediately from UBWA — they have nowhere to go yet, but UBLDC does not throw them away. They land in a per-market init_buffer.
In parallel, UBLDC checks the current Binance API weight before asking for a snapshot:
if current_weight['weight'] > 2200 or current_weight['status_code'] != 200:
# Too close to the rate-limit ceiling, wait it out.
continue
This is a small detail with a big production effect: UBLDC will not blindly hammer Binance with snapshot requests for 50 markets at once and then act surprised when rate limits bite. It yields when the weight is high.
When the snapshot arrives, the loop replays the buffered events, hunting for the sync point. Spot:
U <= lastUpdateId + 1 <= u
Futures / options:
U <= lastUpdateId <= u
The first event that matches flips is_synchronized = True. Anything buffered after that point gets applied with normal gap detection.
European Options has its own quirk — the snapshot's lastUpdateId can lag the live stream by ~30 seconds because Binance caches the snapshot server-side. UBLDC handles this by not dropping the buffer between failed sync attempts: events older than the snapshot get pruned, the rest is kept (capped at 10k) and replayed against the next snapshot. Without this you get an infinite resync loop and a very bad afternoon. With it, options markets just take a bit longer to come online.
Steady state
Once is_synchronized is True, the loop is short:
# Spot:
if event['U'] != last_update_id + 1:
set_resync_request(market) # gap → re-init from scratch
continue
# Futures / options:
if event['pu'] != last_update_id:
set_resync_request(market)
continue
apply_updates(event)
last_update_id = event['u']
A single missed sequence number flips the cache out of sync and triggers a fresh snapshot. That is the entire point: a loud resync beats a quiet lie every time.
The orphaned-levels fix
Binance's diff stream guarantees consistent updates for the top 1000 levels of the book. When a level falls out of the top 1000 it stops getting updates — including delete events. A library that follows the spec literally accumulates ghost orders below the active band. The book grows a basement of dead orders nobody updates.
UBLDC actively prunes this by sorting the cache by price and dropping everything past the limit_count you query with — not just at read time, but as a _clear_orphaned_depthcache_items() pass during diff application. That is also why the ghost-orders post is its own writeup: the bug is in Binance's spec, not in any one client, and most production order books out there have it.
Periodic refresh
refresh_interval lets you force a periodic resync — say, every hour — even if no gap was detected. This is a belt-and-braces defence for very long-running processes. The default is None (don't), and you should leave it alone for normal workloads. Setting it too aggressively rebuilds caches that were perfectly fine, which costs Binance API weight and opens a window where the cache is in init state.

What UBLDC exposes upward
After all of this, UBLDC offers a flat synchronous API:
ubldc.is_depth_cache_synchronized(market="BTCUSDT") # → True / False
ubldc.get_asks(market="BTCUSDT", limit_count=5)
ubldc.get_bids(market="BTCUSDT")
Notice what is not there: there is no get_asks_or_die_silently(). The synchronization status is a separate, queryable signal. Consumers can ask it before reading, or — more usefully — handle the case where a read happens during a resync. That is the seed of the trust layer pattern.
Layer 3 — UBDCC: the cluster
If you only need one Python process, UBLDC standalone is enough. UBDCC is what you reach for when the answer to "where does the order book live?" stops being "inside this script" and starts being "as a service my team can rely on without babysitting it".
The cluster is three roles. Nothing magical. No ceremony. Plain HTTP/JSON between them:
mgmt(one) — owns the authoritative cluster DB: which markets exist, which DCN holds which replica, which API keys are mapped to which DCN. Distributes work. Serves write-side endpoints (/create_depthcache,/add_credentials, …). Backs itself up to every other node on every sync cycle.restapi(one to many) — public entry point. Looks up which DCN is responsible for a(exchange, market)query, routes to it, fails over to a replica if the primary doesn't answer, and surfaces the failover in the response so monitoring sees it.dcn(many) — each DCN runs one UBLDC manager and N markets. One DCN per CPU core is the rule of thumb (Python's GIL caps a single process to one core). Serves/get_asks//get_bidsdirectly.

Three architectural decisions are worth flagging because they look small and pay off enormously.
Disposable cache, durable contract
A DCN is replaceable. It is not precious. It holds a few in-memory order books and a WebSocket connection. Kill it, and the only loss is the time it takes mgmt to assign its markets to a different DCN and for that DCN to re-sync. The cluster DB is replicated to every node on every sync cycle, so even mgmt is replaceable — restart it and it pulls the most recent backup from whichever node has the freshest copy.
The takeaway from one of the LinkedIn replies sharpened this for me:
"REST queries over stateless cache means you spin replicas up and down without choreography, completely changing how you think about failover." — Peter Andreas
Exactly. The fragile thing in most setups is the cache itself. Treating cache replicas as cattle, not pets, is the entire reason failover is boring. And boring failover is good failover.
error_id #6000 — the trust signal on the wire
When a DCN gets a query for a market that is currently out of sync, it does not return last-known-good data with a happy 200. It returns this:
return self.get_error_response(
event=event,
error_id="#6000",
message=f"DepthCache '{market}' for '{exchange}' is out of sync!"
)
That is the trust state crossing the network boundary. This is the moment where UBDCC stops being "a cache" and becomes a contract. The consumer now has three explicit options instead of one implicit one:
Wait — poll again in a moment, the cluster is re-syncing.
Reduce confidence — the strategy can still trade, but with a wider risk margin until the cache is back in sync.
Refuse — for strategies where stale data is worse than no data, the right move is to step out of the market entirely.
That decision belongs to the consumer, not to the cache. The cache should not cosplay as a risk engine. UBDCC's job is to preserve the trust signal across the boundary so the consumer is never accidentally trading on a stale book.

Replicas + staggered start
When you create a DepthCache with desired_quantity=3, mgmt picks three different DCNs for the three replicas and staggers their start times by a few seconds. That is deliberate, not cosmetic. Three parallel snapshot requests for BTCUSDT are three identical hits on Binance with no fault-tolerance benefit; staggering them means each replica is independently synced at a slightly different point in time, which also means at most one is ever in resync at any given moment under normal conditions. Failover stays cheap.
Replicas live on different DCNs by design. Mgmt's distribution scheduler refuses to put the same market twice on the same node — otherwise you would have "redundancy" that dies with a single process.
What's not there
No Redis. No PostgreSQL. No etcd. Not because those tools are bad — because this problem does not need them at the core. The cluster DB is a Python dict that mgmt replicates to every other node on each sync cycle. This is a deliberate constraint: every external dependency you add is one more thing that needs to be deployed, secured, monitored and recovered. UBDCC's recovery story is "pick the node with the most recent backup, re-elect mgmt, done".
No transport encryption inside the cluster. Yet. The internal API is plain HTTP. This is a known gap, documented honestly in the README: the assumption is that you firewall the cluster off and run it behind a private network. We are building from the core outward, not from the buzzword inward.
No bot logic. UBDCC does not place orders, run strategies, generate signals, or move funds. It is the data layer you build those things on top of. If you want a trailing stop loss, that is UBTSL. If you want raw streams, that is UBWA.
Layer 4 — The dashboard: the trust layer for humans
The cluster speaks JSON. Operators speak in glances. If you need to read a log line to know whether the book is trustworthy, the UI is not doing its job.
The UBDCC Dashboard is a single-page browser app — vanilla JS, no framework, no tracking, served by a stdlib HTTP launcher — that turns the cluster's existing endpoints into a live operations view. It does not introduce new state; everything you see is something the cluster already knows.
Three things are worth zooming in on:
Mini-orderbook tiles. Each DepthCache is a compact tile with top-3 asks/bids, quantity bars, and a spread in basis points. An
IntersectionObserverplus a filter gate ensures only on-screen, matching tiles poll the cluster. You can have 600 caches and still scroll a smooth 2-second refresh.Trust state at a glance. Out-of-sync (
#6000) tiles turn red. Other errors turn yellow with a compact message. The Cluster Status modal in the header (Pods / DepthCaches / DCNs / Credentials tabs, plus a pinned health strip) gives you the same view at the cluster level: per-DepthCache replica donut, distribution state, sync state.API Builder. Pick an endpoint, fill in a form, get a copyable snippet in curl, HTTPie, Python (using the official UBLDC
Clusterclient), JavaScript, Go, C#, Java, Rust, PHP or C/C++. ATry it →button runs GET-safe calls through the dashboard's CORS proxy and pretty-prints the JSON. This is how non-Python developers onboard onto the cluster — and, honestly, how I test endpoints when I do not feel like typing curl for the hundredth time.


The dashboard is also where the Credentials Manager lives (masked previews, two-click remove), the Add DepthCaches modal with live exchangeInfo symbol lookup, and the bulk × Remove filtered with a two-click confirmation that is only enabled when a filter is active — so you cannot accidentally wipe the cluster with one slip.
Where this is going next: gRPC
REST is a perfect onboarding contract. Anything HTTP-capable can read the cluster. That is hard to beat for "I want to be productive in 90 seconds".
For tight-loop consumers — market makers, arbitrage engines, anything that wants top-of-book fast enough that JSON starts to feel like furniture in the hallway — REST becomes the long pole. JSON parsing alone is often more expensive than the actual cluster- internal lookup. Long-poll patterns also fight against a stateless read API.
The next architectural step we are looking at is a gRPC contract alongside REST, not instead of it:
Streaming reads. Subscribe once to
(exchange, market, limit_count)and receive a server-pushed update on every diff the cluster applies — including atrust_statefield that isIN_SYNC/OUT_OF_SYNC/RESYNCING. Same trust contract as theerror_id #6000you get from REST, just delivered as a first-class field on every message instead of an exceptional response. Order-book deltas become a typed event stream.Bidi for write-side ops.
create_depthcachesover a streaming RPC means the dashboard (and any operator tool) can show progress per market —pending → starting → synchronized— without polling.Schema-first. Protobuf gives every language the same typed contract for free, including languages where the current REST approach forces hand-rolled DTOs.
REST stays for everything onboarding-shaped. gRPC is the path for high-throughput, low-latency reads where the trust signal needs to ride on the data instead of on top of it. This is idea stage — it is on the roadmap, not in the next release. If your use case sharpens the requirements, the issue tracker is the right place to push.
What this stack is — and what it composes with
Stack-from-the-bottom, one line each:
| Layer | What it owns |
|---|---|
| UBWA | TCP, reconnects, stream signals, async queue per stream |
| UBLDC | One process, N markets, sync state machine, gap & ghost-order handling |
| UBDCC | A cluster of UBLDC processes with replicas, failover and a public REST contract |
| Dashboard | The same trust state, rendered for humans |
What it composes with:
UBTSL — trailing stop loss engine. Reads UBDCC for the order book it trails against, places orders via UBRA.
UBRA — REST client for everything that is not market data: account, orders, balances. Pairs naturally with UBDCC for read.
UnicornFy — raw-payload normalizer. If you read from UBWA directly (rather than via UBLDC/UBDCC), UnicornFy is what gives you uniform Python dicts.
Anything else. Node.js dashboard, Go execution engine, Rust research tool, C# alerting service — they all read the same trust-aware REST contract. That was the goal from the start.
The point
The reason this writeup is structured the way it is — Layer 0 to Layer 4 — is not just to tour the stack. The stack is documented in each repo's README. The point is that trust is not a feature you bolt on. It only works if every layer preserves it.
If UBWA hides reconnects, UBLDC cannot detect a real Binance gap. If UBLDC silently keeps an out-of-sync book, UBDCC has no honest status to report. If UBDCC returns 200 with stale data on #6000, the consumer's strategy is trading on a lie with a nice HTTP status code. Each layer's job is to either preserve the trust signal or fail loudly enough that the layer above can.
The infrastructure fails loudly. The API contract preserves the signal. The consumer makes an explicit decision instead of accidentally trading on stale state. That is what an order book trust layer is for. Not to make the market safe. To stop your own infrastructure from pretending it knows more than it does.
UBDCC, UBLDC, UBWA, UBRA, UBTSL, UnicornFy and the dashboard are all MIT, all on PyPI, all developed in the open. Repos:
unicorn-binance-suite (umbrella)
Star what is useful. Break what is wrong. Open issues where the contract is unclear. Or drop into the unicorndevs Telegram.
I hope you found this informative and useful.
Follow me on Binance Square, GitHub, Mastodon, X, and LinkedIn, or join Telegram for updates on my latest publications. Constructive feedback is always appreciated.
Thank you for reading, and happy coding! ¯\_(ツ)_/¯




