Passing Binance Market Data to Apache Kafka in Python with aiokafka
Learn how to create an Apache Kafka cluster and store Binance data in it in real time.
Note (2026): CloudKarafka has discontinued their hosted Kafka service — a more up-to-date tutorial on Kafka alternatives is coming soon!
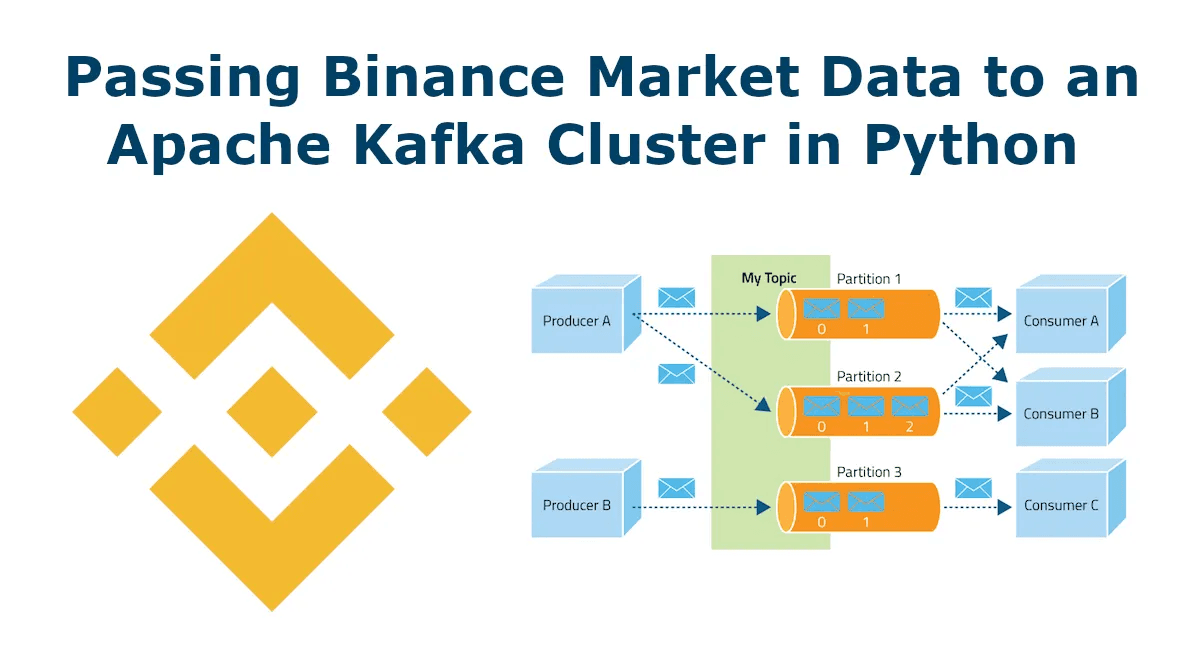
Using a message queuing cluster like Apache Kafka is an excellent solution for handling a large amount of real-time data from Binance in a redundant and scalable way. Apache Kafka is designed to handle high-volume real-time data streams, providing efficient and reliable message queuing and streaming capabilities. By setting up a Kafka cluster, you can ensure that your data is replicated across multiple nodes and partitions, allowing for failover and high availability.
Additionally, Kafka's distributed architecture allows for easy scaling as your data needs grow. This makes it an ideal solution for processing Binance's real-time data, which can be particularly high volume and time-sensitive.
With Apache Kafka and the Python libraries UNICORN Binance WebSocket API and aiokafka, you can build a robust and scalable real-time data processing system that can handle even the most demanding workloads.
Okay, what are you going to learn here?
First, we'll create a free trial system for you at CloudKarafka. This is a cool Kafka cloud service where you can get free access to a shared Kafka cluster consisting of three cluster nodes within minutes and without any significant configuration, and use and test both SSL and user authentication. In the free version, you can manage the Topics via a web interface and produce and consume them manually in the web interface as well as automatically via a websocket connection. The service is optionally hosted on AWS, Google or Azure and you can also choose the geo location.
If you like CloudKarafka's service, you can upgrade to a professional paid subscription that includes many more features such as logging, monitoring, and other security features like firewall, certificates, users, ACLs and more. Their support chat is very fast and helpful.
After that I will show you how you can receive data of any kind from Binance via websocket connection in real time with the UNICORN Binance WebSocket API and send it asynchronously to the Kafka cluster with the library aiokafka.
To make the tutorial complete, we will read (consume) the data from the Kafka cluster with a separate Python script. You can extend this script according to your needs and run it in separate distributed processes to share the load of data processing.
Reading instructions can also be funny and so I don't want to deprive you of these two illustrations that made me smile while researching on https://www.confluent.io/blog/apache-kafka-vs-enterprise-service-bus-esb-friends-enemies-or-frenemies:

Microservices WRONG

Microservices CORRECT
The blog article from Confluent is also worth reading apart from the two funny pictures (I hope you share my humor), but I guess if you read this, you already understood what it's about. So let's get started!
Table of Contents
Creating the Apache Kafka test environment
Receive data from Binance and throw it into the Kafka cluster
Read the data from the Kafka cluster
1. Creating the Apache Kafka test environment
The first step is to sign up for CloudKarafka for free: https://customer.cloudkarafka.com/login
Register with your email address, GitHub or Google account. After signing up, you will first be asked to create a team. Fill out the page and click on "Create team".

If that worked, you have the option to create a new instance.

Don't let the yellow warnings make you nervous, no personal data is required for the trial version.

Now you can choose who can host your project and where this should be done. Click on "Review" to continue.

If everything fits, confirm the configuration and create the instance.

Now your shared Apache Kafka instance is available. To manage it, please click on the instance name.

Note the values of these parameters from the "OVERVIEW": Hostname, Default user, Password and Port

The goal of this example is to read from the Binance "trades" webstream the price of each trade from specified markets in real time and pass it to Kafka. Assuming we receive the information of the trades for the markets "btcusdt", "ethusdt" and "ltcusdt", it would be practical to create the following topics for them: "btcusdt_binance_spot_last_trade_price", "ethusdt_binance_spot_last_trade_price", "ltcusdt_binance_spot_last_trade_price"
To get to the corresponding interface click on "KAFKA" in the left menu and then on "TOPICS".

Create the topic "btcusdt_binance_spot_last_trade_price".
Note: Please note that in the free trial version of CloudKarafka a prefix must be used! In this example the prefix is "pfyrfgiv-". Therefore the final name is "pfyrfgiv-btcusdt_binance_spot_last_trade_price". For a free test this is good enough!

Repeat the last step and create more topics for "ethusdt_binance_spot_last_trade_price" and "ltcusdt_binance_spot_last_trade_price".
This completes the setup of the Kafka cluster and we can start creating the Python script.
2. Receive data from Binance and throw it into the Kafka Cluster
For the Python script to work, we first install the dependencies:
$ python3 -m pip install aiokafka --upgrade
$ python3 -m pip install unicorn-binance-websocket-api --upgrade
Since as of today (29–03–2024) kafka-python has released many updates but no new version since 2020, I recommend installing kafka from GitHub:
$ python3 -m pip install git+https://github.com/dpkp/kafka-python.git
Copy or download the following Python script and paste your Kafka credentials:
https://gist.github.com/oliver-zehentleitner/92b632f582df22523b1d5593faa0a4f4
If you have followed the previous instructions 1 to 1, the script is now ready and can be started by you!
I hope everything works out for you so far, should anything go differently for you, feel free to write me in the comments. But in any case take a look at the created logfile, it should be named like the executed script with ".log" at the end.
3. Read the data from the Kafka cluster
The easiest way to check and admire your work is to open CloudKarafka browser and activate a "Consumer".

Activate the Consumer for the Topic "your_prefix-btcusdt_binance_spot_last_trade_price" — this Topic usually has the highest trade frequency.

When you put everything together so far, this is what it looks like:
But now we want to fetch the data with a Python script so that you can process them as you like. This script Consumes the "your_prefix-btcusdt_binance_spot_last_trade_price" Topic, you only have to replace the login data and the topic prefix with yours.
https://gist.github.com/oliver-zehentleitner/3750a202a3e729ae8147aa08c7f46289
Copy the script twice and change the topic once to "your_prefix-ethusdt_binance_spot_last_trade_price" and once to "your_prefix-ltcusdt_binance_spot_last_trade_price".
Now you should have a complete system with one data collector and three data processors that allows you to receive data from Binance via websocket and process it via a Kafka cluster in separate distributed applications.
Of course, you could also redundantly receive and feed into Kafka and create multiple consumers for a Topic. I hope you have understood the basic concept and can now adapt it according to your ideas and requirements. 🚀
I hope you found this tutorial informative and enjoyable!
Follow me on Binance Square, GitHub, Mastodon, X and LinkedIn to stay updated on my latest releases. Your constructive feedback is always appreciated!
Thank you for reading, and happy coding!




